Présentation de la stack Elastic
Stack Elastic : ElasticSearch, Logstash, Kibana, Beats
Un fichier de log est un fondamental dans le cadre du développement logiciel. De nombreuses applications inscrivent ainsi leurs activités dans ces fichiers dédiés, notifiant des événements significatifs, tels que des erreurs importantes ou des crashs d’une application. Ainsi, la recherche d’erreur et la compréhension de leur contexte est facilitée avec ces historiques.
Ces fichiers contiennent peuvent ainsi contenir plusieurs dizaines de milliers de lignes par jour, selon les applications. Les opérations de recherche à base de grep, tail voir de CTRL+F peuvent facilement devenir fastidieuses.
Présentation de la stack
La Stack Elastic pour Beats, ElasticSearch, Logstash et Kibana, est un agrégat logiciel dédié à la collecte d’informations significatives de vos applications, de leur centralisation et de leur synthèse graphique.
En bref, les agents Beats collectent des informations sur des systèmes distants et abstraient leur transmission à une ou plusieurs destinations distantes.
Logstash est un outil dédié à l’extraction d’informations depuis des sources de données hétérogènes, leur transformation et leur transmission.
ElasticSearch permet de réaliser un moteur de recherche. Il fournit un service d’interrogation et gestion des données s’appuyant sur une architecture REST. Ce service est consommé par l’application web Kibana, exposant une interface graphique simple d’utilisation permettant à l’utilisateur de monitorer en temps réel l’état des fichiers log.
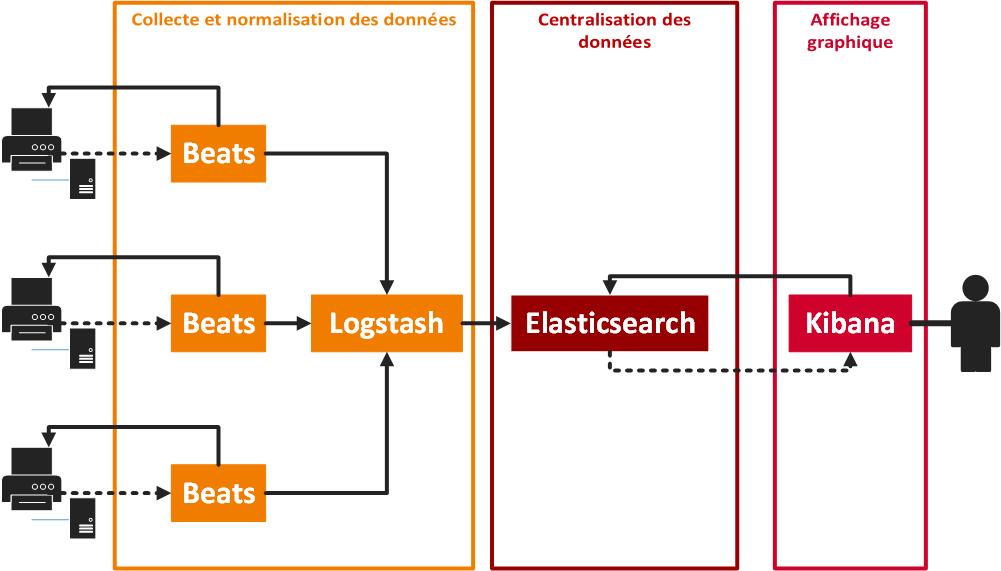 Structure d’une stack Elastic
Structure d’une stack Elastic
 Un fichier de log
Un fichier de log
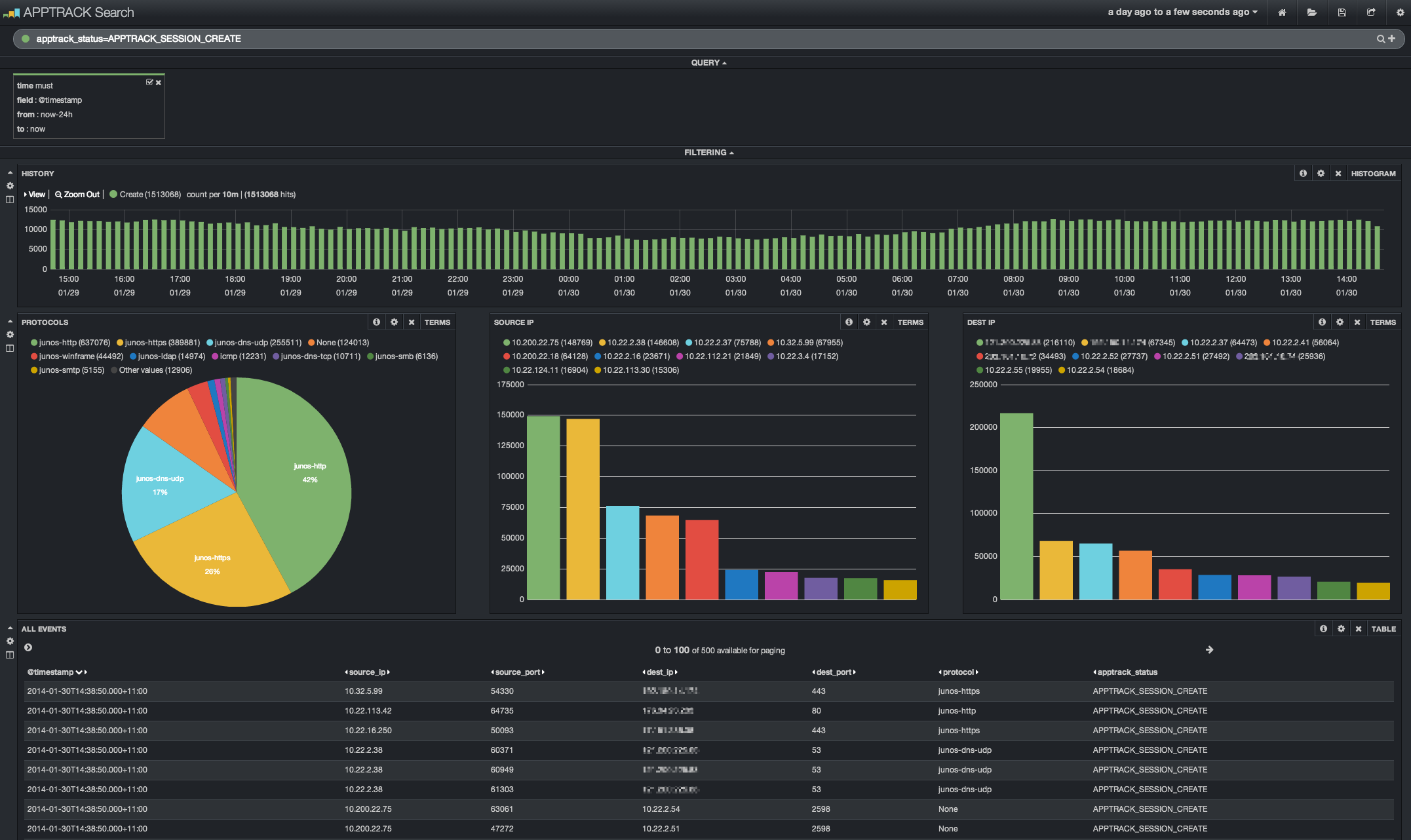 Interface Kibana présentant une synthèse graphique de données
Interface Kibana présentant une synthèse graphique de données
Ces outils sont proposés par l’entreprise Elastisearch BV. Ils peuvent être utilisés librement et gratuitement dans leur version OpenSource.
L’entreprise propose également des forfaits payants, proposant des solutions hébergées déjà configurées. cf Website https://www.elastic.co/found/pricing.
Logstash
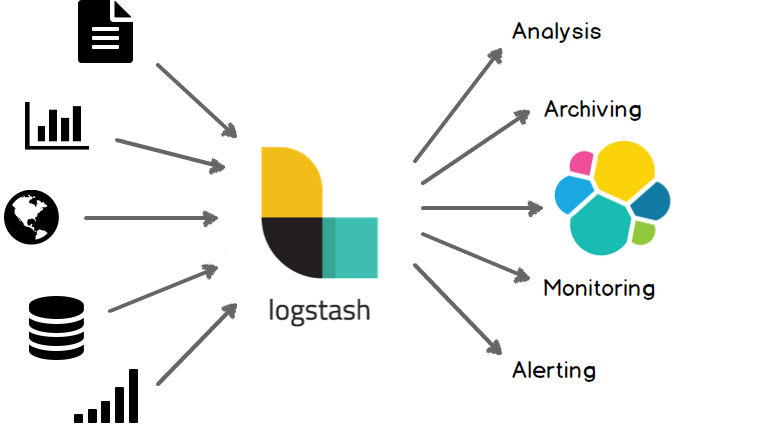 IllustrationLogstash
IllustrationLogstash
Logstash is an open source data collection engine with real-time pipelining capabilities. cf Documentationhttps://www.elastic.co/guide/en/logstash/current/introduction.html
Logstash est un outil dédié à la transformation et à la transmission de données issues de sources diverses aux formats hétérogènes. Ainsi, il extrait des données issues de sources variées, les formate vers une autre structure de données et les transmet selon plusieurs protocoles, tels que le chargement en base de données, le protocole http…
Logstash fonctionne en trois étapes séquentielles :
- l’extraction des données (Input)
- la normalisation (Filter)
- la transmission des données (Output).
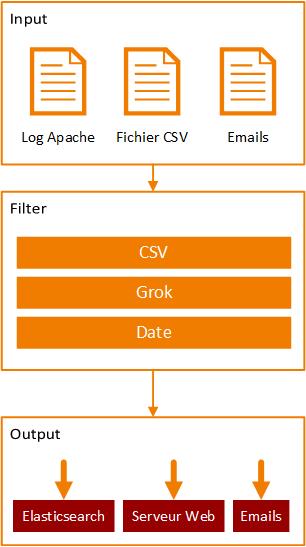 Diagramme de la pipeline Logstash
Diagramme de la pipeline Logstash
L’étape d’extraction décrit les sources de données. Logstash s’appuie sur un écosystème fournit de plugins. Il est ainsi possible de récupérer des données depuis un fichier, une requête SQL, un flux twitter, un fichier csv… Certains plugins fournissent des options de configuration supplémentaires permettant d’affiner l’extraction des données.
L’étape de transformation s’appuie sur les informations récoltées à l’étape précédente afin de construire la structure de données à retourner. Plusieurs sous-opérations de transformation peuvent se succéder afin de construire de manière itérative le résultat attendu.
L’étape de transmission envoie l’information construite à l’étape précédente aux destinations mentionnées. Il est possible de réaliser des requêtes Http, SQL ou d’envoyer des e-mails depuis ce procédé.
Nous reviendrons sur les étapes de configuration de Logstash plus en détail dans un article dédié. La démonstration par l’exemple sera plus explicite.
Bien qu’à l’origine l’outil ait été conçu pour parser les fichiers de log, il est parfaitement utilisable dans d’autres contextes. Son objectif premier est de s’inscrire en tant qu’outil ETL (Extract Transform Load). Dans le cadre de fichiers de log, il simplifie les processus de d’extraction des informations, de transformations et de transmission.
Référence
- Elasticsearch BV, Logstash Introduction, https://www.elastic.co/guide/en/logstash/current/introduction.html, 2016
ElasticSearch
Elasticsearch is a distributed, open source search and analytics engine, designed for horizontal scalability, reliability, and easy management. It combines the speed of search with the power of analytics via a sophisticated, developer-friendly query language covering structured, unstructured, and time-series data. cf Websitehttps://www.elastic.co/products
Elasticsearch est un moteur de recherche opensource. Il fournit des fonctionnalités de stockage, d’indexation et recherches avancées sur une base de données orientée document.
Les bases de données orientée document est spécialisée dans le stockage et les opérations de traitement sur des données atomiques et indépendantes. L’avantage de ces formes de bases de données est la facilitation des opérations réplication et de séparation des données dans des espaces de stockages différents. En effet, il est plus simple de dupliquer une entité indépendant qu’un ensemble relationnel tentaculaire.
L’approche non relationnelle facilite la clusterisation de l’application et sa montée en échelle. Ainsi, vous pourrez traiter des téraoctets de données simplement avec un cluster Elasticsearch réparti sur des systèmes distants.
Chaque document traité par l’outil est ainsi indexé en respectant des opérations successives permettant d’extraire des informations significatives. Ces opérations d’indexation facilitent les opérations de traitement et de recherche. Grâce à ces opérations d’indexation, les requêtes pourront ainsi gérer des notions de synonymes, de recherche par construction phonétique, voir même des notions de traduction. Ces opérations sont paramétrables et peuvent être enrichies par les nombreuses extensions existantes.
Elasticsearch fournit une interface d’utilisation s’appuyant sur une architecture REST permettant d’indexer des documents, de gérer les index générés et d’administrer l’outil.
Cette interface s’appuie sur un format de requête très spécifique, que l’on peut catégoriser de DSL (Domain Specific Language / langage dédié). Ce format permet de créer des requêtes avancées alliant combinaisons de critères, opérations de filtrage, tri, pagination des résultats…
Dans le cadre de la stack Elastic, la configuration de l’outil est minimale. Logstash transmet les données transformées à Elasticsearch. Ces données sont indexées. Kibana utilise nativement l’interface REST afin de récupérer les données indexées. Cela est complètement transparent pour l’utilisateur.
Références
- Jonathan Baranzini, Elasticsearch : introduction, http://www.stepinfo.com/2013/12/elasticsearch-introduction/, 11 décembre 2013
- TLeroux, Premiers pas avec ElasticSearch, http://blog.zenika.com/2012/11/14/premiers-pas-avec-elasticsearch-partie-1/,14 novembre 2012
- Elasticsearch BV, Elasticsearch Reference, https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
Kibana
. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps. cf Websitehttps://www.elastic.co/guide/en/kibana/current/introduction.html
Kibana est une plateforme opensource de visualisation des données, conçue pour fonctionner conjointement avec Elasticsearch.
L’outil permet ainsi de construire graphiquement des requêtes sur les données, tout en proposant un affichage en temps réel de leurs résultats.
Puis, il est possible de construire des graphiques, tels que des histogrammes, des courbes, des secteurs… Chaque graphique est ensuite enregistrable, maintenable et chargeable.
Kibana permet également de construire des Dashboard personnalisés. Ceux-ci décrivent graphiquement l’états de plusieurs données en temps réels. En effet, il est possible de configurer l’application pour que les données soit rafraîchies automatiquement.
On dispose à terme d’un tableau de bord graphique, permettant en un clin d’oeil de connaître l’état de plusieurs ensembles de données.
Références
- Elasticsearch BV, Kibana User Guide, https://www.elastic.co/guide/en/kibana/current/index.html
La puissance de la stack
Elasticsearch, Logstash et Kibana ont été conçus telle que leur combinaison soit naturelle. En effet, Logstash permet de transformer nos fichiers de log et de les envoyer à Elasticsearch. Elasticsearch fournit des fonctionnalités des recherches avancées qu’utilise Kibana. L’utilisateur pourra ainsi construire des Dashboards personnalisés, croisant les différents informations issus des fichiers de log.
Leur liaison est native et les fichiers de configuration sont déjà prévus à cet effet.
A terme, plusieurs services seront exposés sur le serveur dédié à cette Stack. Kibana sera accessible de manière graphique et permettra de consulter et construire les dashboards, d’effectuer des requêtes sur les log de manière graphique.
Elasticsearch fournira une API REST exposant les données au format JSON. Il est ainsi possible de consulter les données des log, les mettres à jour et les supprimer.
Enfin, Logstash exposera deux ports pour que les utilisateurs puissent fournir leurs fichiers de log ou lier ces ports à des agents dédiés au transport de log.
Aller plus loin
Collectes et transmissions étendues
Plutôt que de transmettre manuellement les fichiers de log à Logstash, il est possible d’utiliser des outils dédiés à cette communication. Il s’agit d’applications qui transmettent des log générés à d’autres entités. Filebeat par exemple récupère les dernières informations générées sur les fichiers de log et les transmet à Logstash directement.
Il existe plusieurs autres applications dédiées à des problèmatiques différentes tels que Winlogbeat spécialisé dans la récupérations des log des évènements Windows, Topbeat dédié à la collecte des informations machine tel que la charge du système, la consommation CPU, les données propres au système de fichiers…
Références
- Elasticsearch BV, Beats | Collect, Parse & Ship, https://www.elastic.co/products/beats
Alertes en temps réel
La société en charge de la stack Elastic propose également un produit dédié à la création d’alertes. Ces dernières sont générées lorsque des données remplissent certaines conditions.
A la différence des autres outils exposé dans ce document, ce produit n’est pas gratuit. Au prix du service, il est peut être judicieux d’envisager des alternatives gratuites.
Traitement de masses et exploration de données
En partant du postulat que l’outil Elasticsearch concentre un grand nombre de données normalisées, cela facilite l’utilisation d’outils de traitement de données de masse comme Apache Spark ou Map Reduce.
Il existe un plugin Apache Spark, MLib fournissant plusieurs algorithmes d’exploration de données. Ces algorithmes permettent d’extraire des connaissances à partir de données. Cela peut permettre par exemple d’étudier des phénomènes de corrélations entre données, de définir de modèles de prédiction, de définir des segments de données.
Les résultats de ces algorithmes s’inscrivent dans la thématique de l’informatique décisionnelle. D’un grand volume de donnée on extrait des modèles théoriques significatifs pouvant être utilisés dans une démarche commerciale.
Par exemple, les données peuvent indiquer qu’un site marchand reçoit un grand nombre de visite le vendredi soir et peu le mercredi matin. L’entreprise pourra grâce à ces chiffres envisager d’augmenter la puissance du serveur le vendredi et proposer des promotions ciblées pour attirer du monde le mercredi matin.
Références
- Spark, Machine Learning Library (MLlib) Guide, http://spark.apache.org/docs/latest/mllib-guide.html
Le mot de la fin
Cet article introduit la stack Elastic en présentant succinctement Logstash, ElasticSearch et Kibana. Dans un prochain article, nous illustrerons l’emploi de cette solution dans un contexte précis en partageant avec vous les différentes étapes d’installation, de configuration et d’utilisation.